Apache Storm and the Backpressure Smackdown
01 October 2019 - CommentsApache Storm 2.0 is the first contender into the cage in the Streaming Backpressure Smackdown. Will this first-generation stream processing engine go down in flames, or will it stand up tall? Let’s find out …
Enter Storm
Wikipedia contains a pretty good description of Storm:
Apache Storm is a distributed stream processing computation framework written predominantly in the Clojure programming language. Originally created by Nathan Marz and team at BackType, the project was open sourced after being acquired by Twitter … The initial release was on 17 September 2011.
It is worth noting that Storm 2.0, used for this smackdown, is a rewrite of the original Clojure code in Java1. This latest version includes a new high-level API, much like that of Spark and Flink, in addition to the original low-level API.
By all accounts Storm is the grand-daddy of our contenders and, if you believe some folk, a bit long in the tooth2.
The question is, can Storm still hold its own?
UI Limitations
So no-one is going to kid you that the Storm UI is pleasing to the eye. It isn’t …
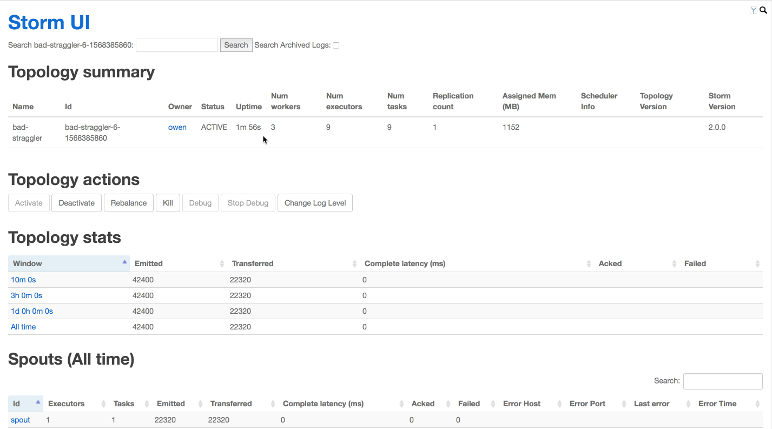
However, looks aren’t everything, as they say. The UI is actually pretty comprehensive, and contains some really useful metrics for identifying the hotspots in your dataflows.
That said, it is sorely lacking when it comes to throughput metrics, where it is limited to three aggregate figures: rolled up at 10 minutes, 3 hours and 24 hours.
Fortunately, like both Spark and Flink, Storm does provide a way to push both platform and application metrics to third-party analytics tools. For the smackdown, we will make use of these to provide us with a higher resolution view of the throughput over time. Specifically, we will use Elasticsearch and Kibana for this task.
Smack. Down.
So let’s get into it. How did Storm cope with our assault course of backpressure scenarios?3
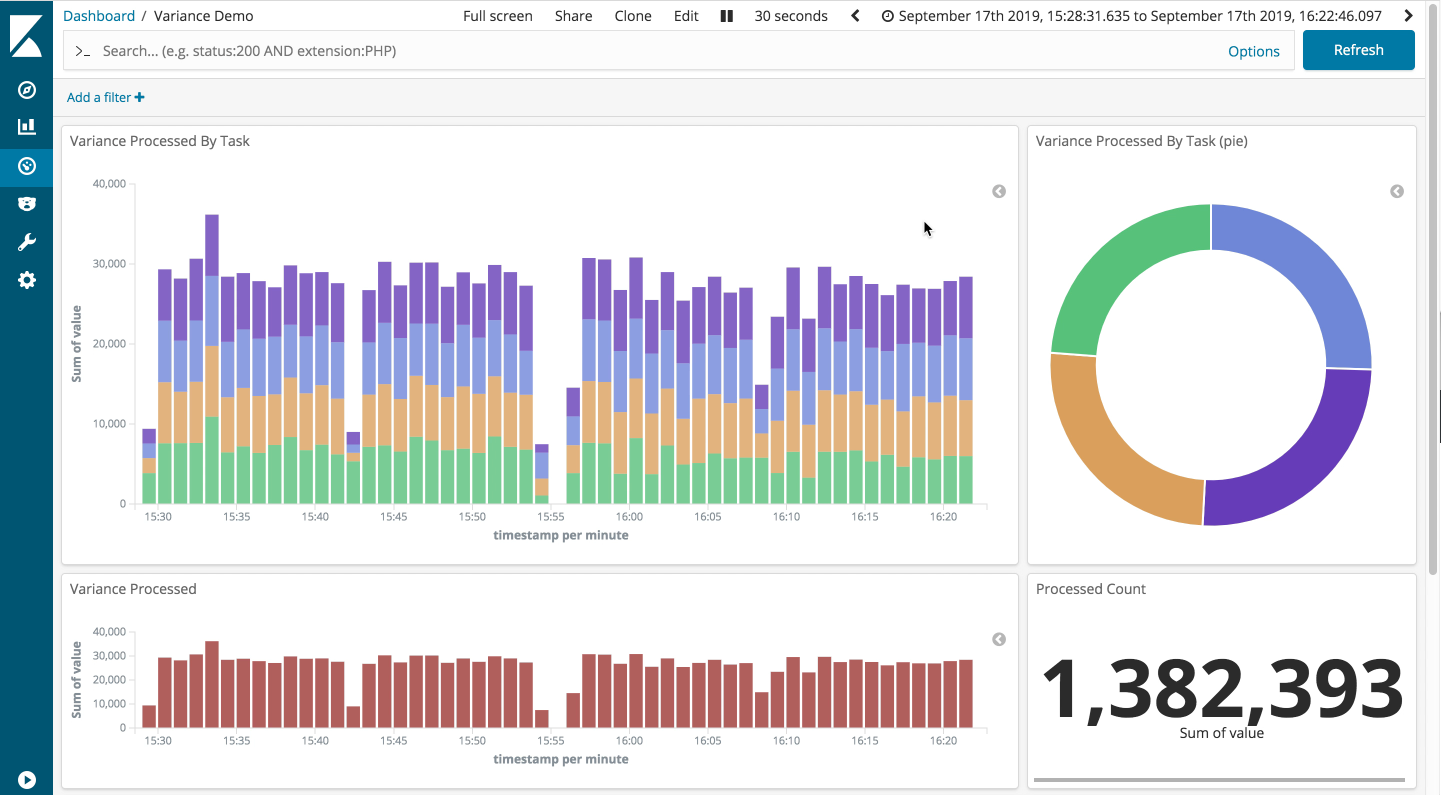
The slight straggler
First up, the slight straggler scenario: easy pass. The dashboard below shows the run of the minimal variance scenario, followed by the slight stragger. As you can see, the throughput is largely unaffected.
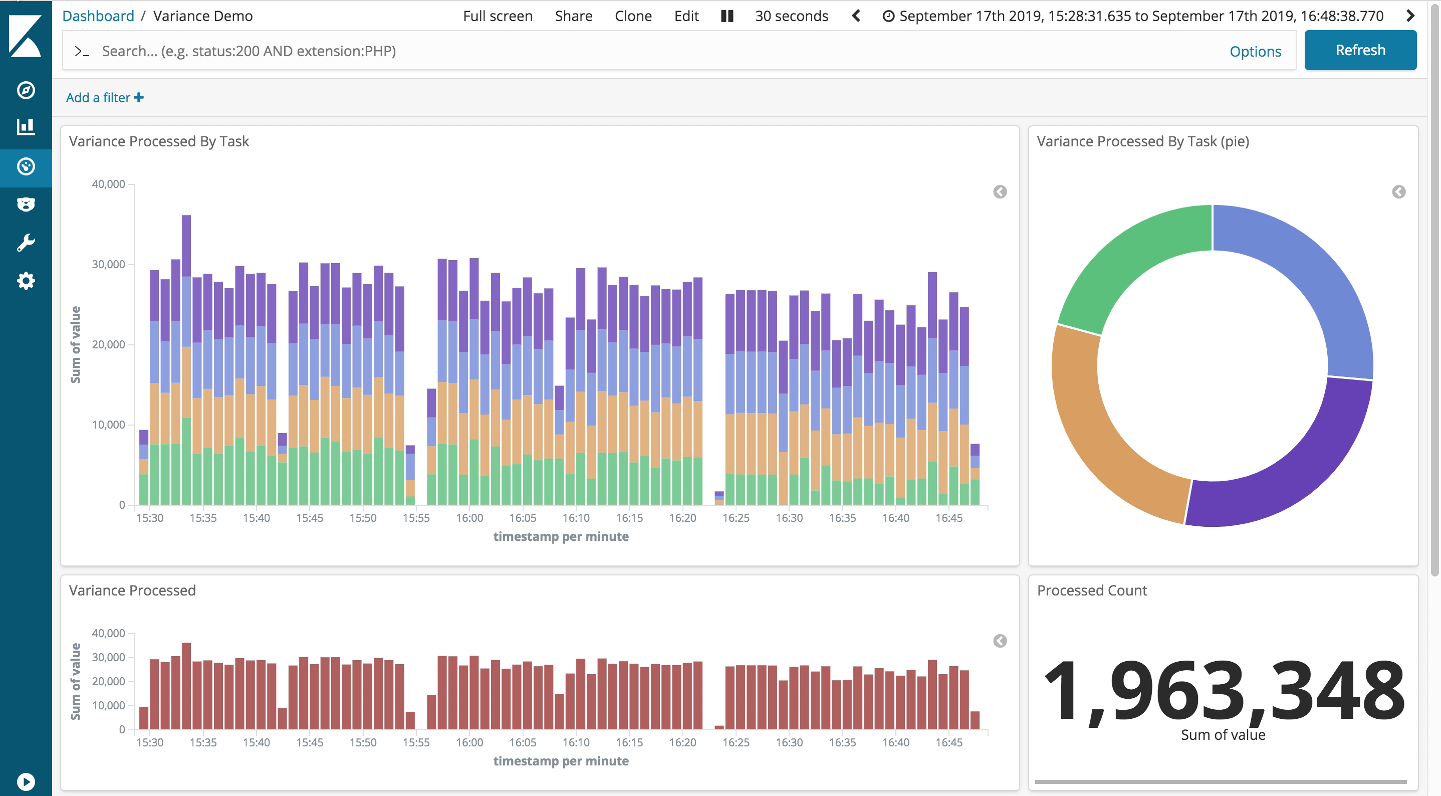
The bad straggler
Next up, the bad straggler scenario: solid performance again. The throughput in this third run, shown below, clearly drops off in comparison to the previous two scenarios. But then we expect this as we are limiting the flow through one of the parallel tasks: you can clearly see the take from the green task is down.
The constant straggler
Finally, the constant straggler scenario: looking good. Again the throughput is down a little as expected. However, the other non-straggling tasks appear to be performing well, even on our gnarliest scenario.
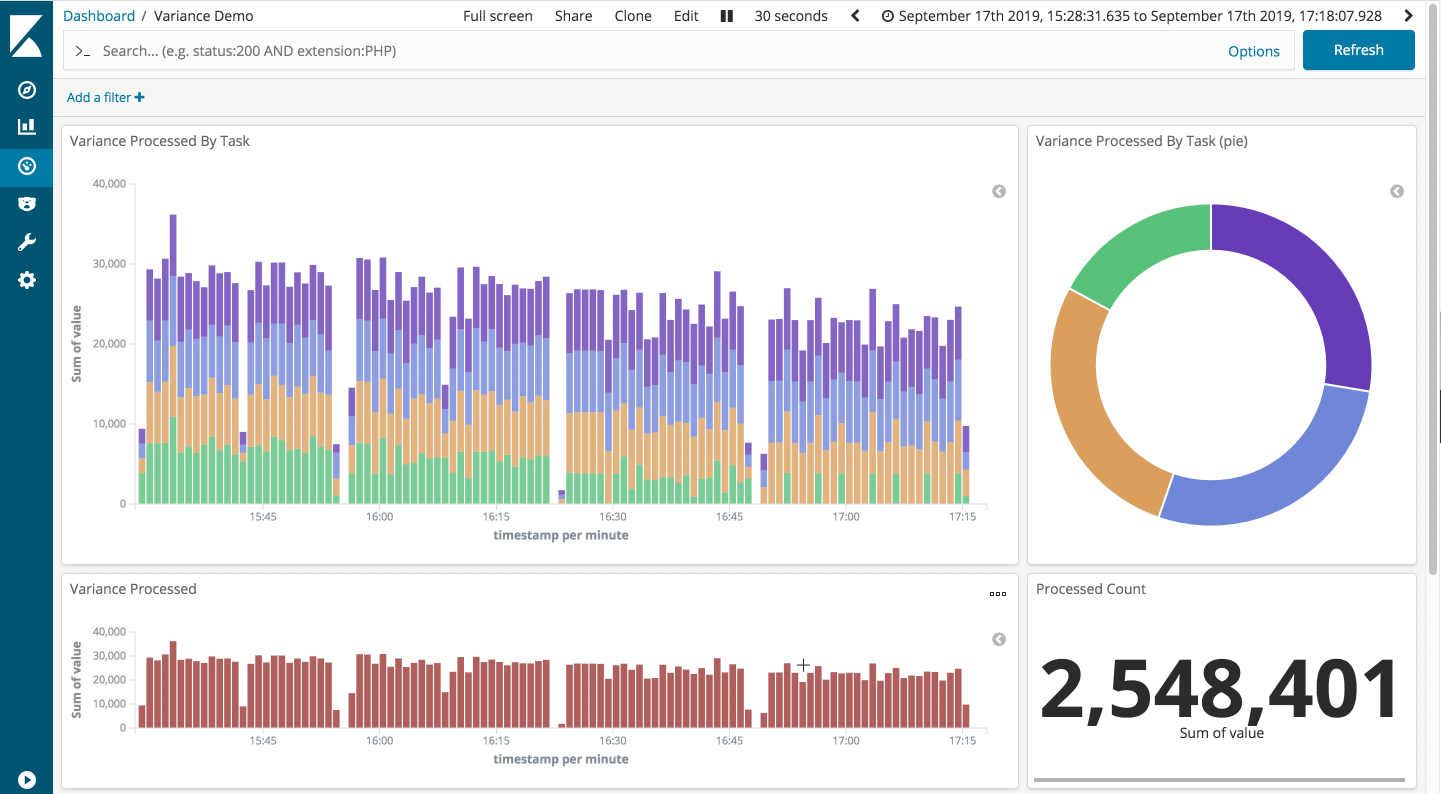
If we filter out the straggling task, we can clearly see the throughput through the remaining tasks is largely unaffected. This demonstrates the robustness of the Storm backpressure implementation.
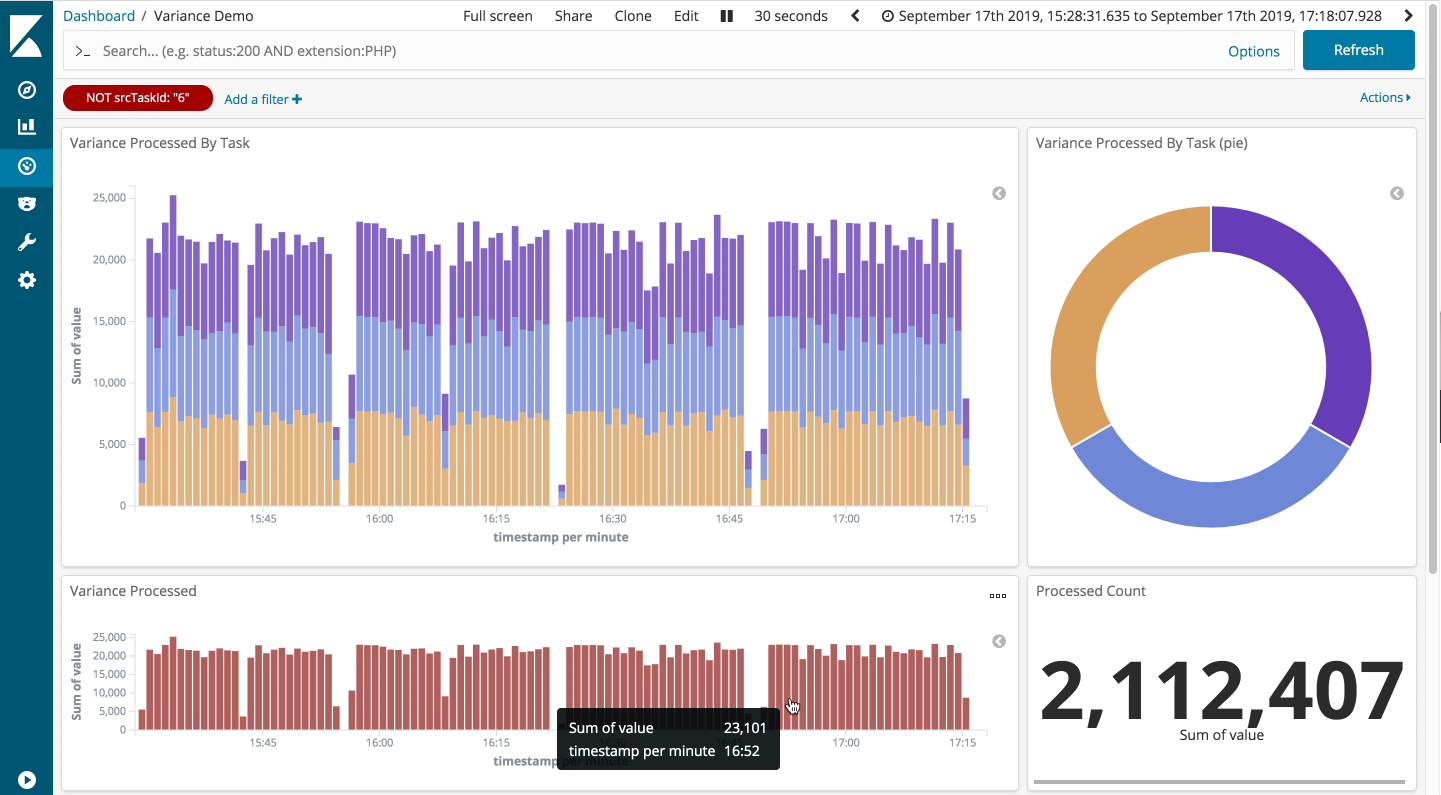
A+ for Storm
For the sake of completeness, I performed a much longer run (> 90 minutes) of the constant straggler scenario to ensure that the backpressure mechanism was being fully engaged. Just in case. As can be seen, it’s pretty flawless.
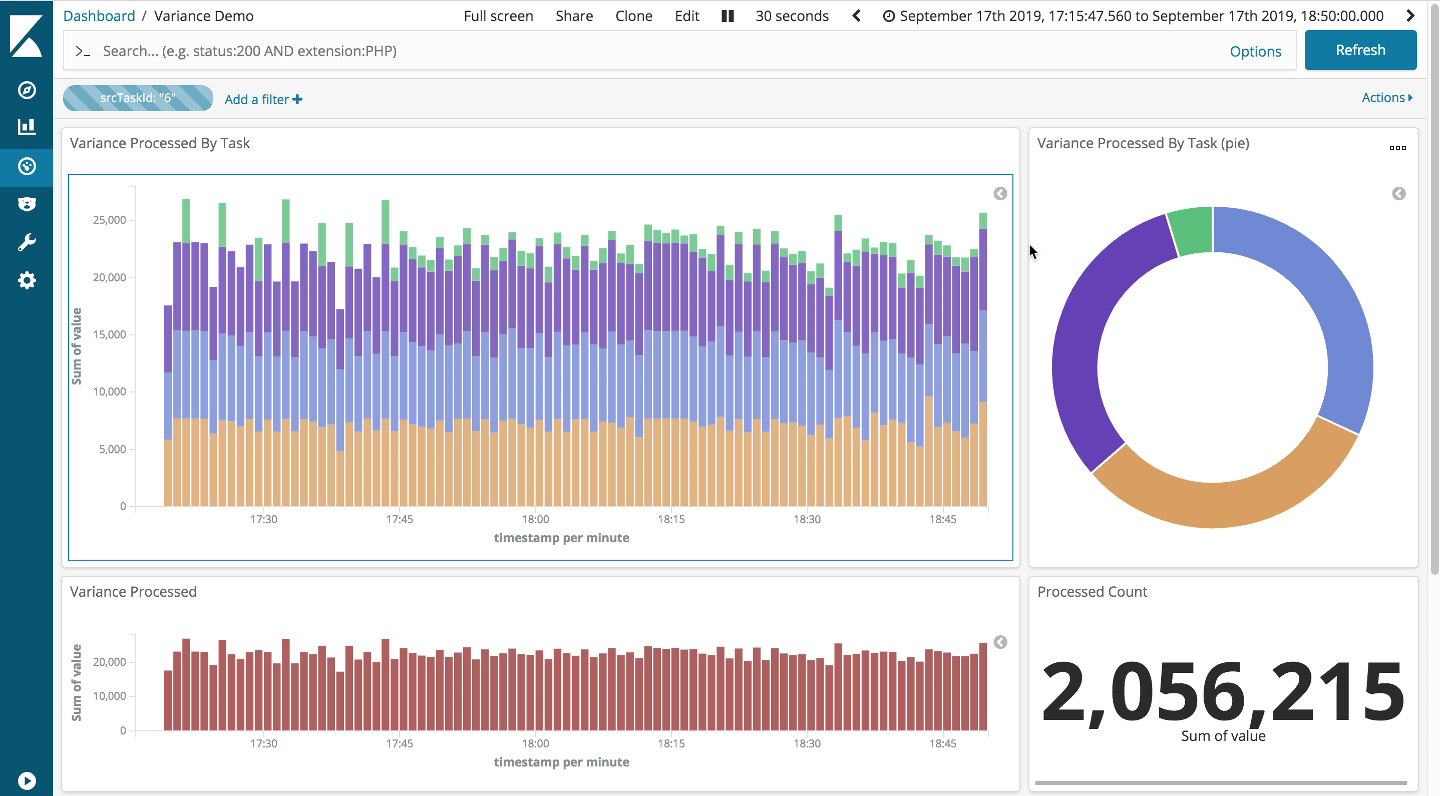
If you want to run these scenarios checkout the code in github, and knock yourself out.
Pleasantly surprised
I have to admit, I was a bit nervous. Having originally set out to demonstrate Storm could still keep up with the newer processing engines, I realised that I had chosen the one area where I had seen previous versions of Storm struggle at times. However, it seems the backpressure implementation in Storm has definitely improved.
I think we can say that, at least in the area of backpressure, Storm can hang with the best of them. As it turns out, this was not the only surprise during the smackdown, but more about that another time …
-
My understanding is that this is largely based on JStorm, a rewrite of Storm in Java that Alibaba opensourced a couple of years ago. ↩
-
Don’t believe the haters - folk like Verizon are still getting great mileage out of Apache Storm. ↩
-
See the first article in this series for a breakdown of the backpressure scenarios. ↩
Tags: Performance Storm Smackdown Big-data Data-Engineering
comments powered by Disqus