Apache Spark - what's the big deal?
21 September 2015 - CommentsIs Apache Spark as significant as the big data vendors are making out? Or is it just all marketing and brand? What is all the fuss about?
Vendor Buzz
Towards the end of 2013, Cloudera came out publically as the first big data vendor to get behind Spark. This had been a while coming, and it didn’t take long for the other key players in the market to follow suit.
The rapid rise of interest in Spark since then can be seen clearly in the Google Trends chart below:
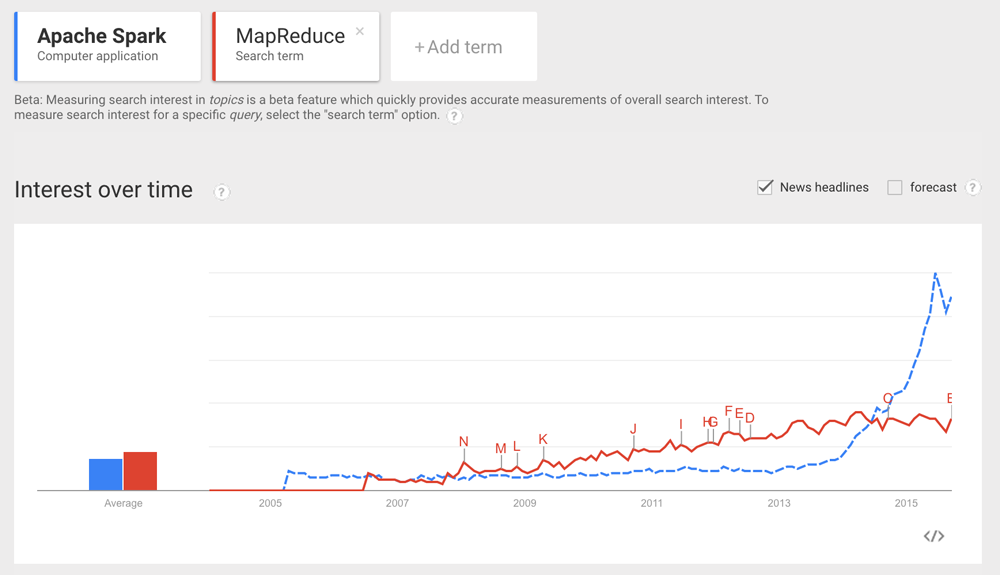
Somewhat late to the party, IBM recently made a major commitment to Spark1; calling it ‘perhaps the most important open-source project of the decade’. This is a pretty bold statement, to say the least. Since then they have been making a considerable effort to align their brand with Spark, as can be seen by their #sparkinsight Twitter hashtag:
Take a look at why IBM is making a strategic bet on #Spark : #SparkInsight http://t.co/1CAavyvIEa pic.twitter.com/qd5TMDxXD4
— IBM Big Data (@IBMbigdata) August 22, 2015
So is this just vendor buzz and marketing? Or is Spark something to get excited about? The short answer is yes, Spark is a big deal. To understand why, you first have to look at what came before: MapReduce.
MapReduce - a very potted history
Rollback the clock 15 years or so, Google were trying to conquer the internet search market. But they had a problem. A big data problem. They wanted to index the internet. Whilst attempting to overcome the technical challenges of running page rank algorithms over vast quantities of data, they hit a fundamental issue that is common amongst big data problems.
MapWhat?
Previous approaches had generally involved moving data from network storage to hugely powerful supercomputers that would run the computations over the data. However, as data sizes increased this became untenable, since the time to read the data from disk and transfer it across the network became the primary constraining factor.
Google solved this problem by designing a system in which the data was partitioned across large clusters of machines. The computation was then taken to the data, executed on each partition of data, after which the results from all the machines were brought together to form the final result.
In 2004, Google published MapReduce: Simplified Data Processing on Large Clusters, outlining the companies approach to processing data at petabyte scale. This followed a year after the release of their ground-breaking paper, The Google File System, detailing their design of a distributed scalable fault tolerant file-system. At this point, anyone processing data at scale stood up and took note.
Enter Hadoop
Imitation, as they say, is the sincerest form of flattery. Yahoo were also trying to index the internet, and had the same technical issues as Google. So, with the help of Doug Cutting, they quickly set about creating their own implementation of MapReduce and GFS. This project was open-sourced and Hadoop was born.
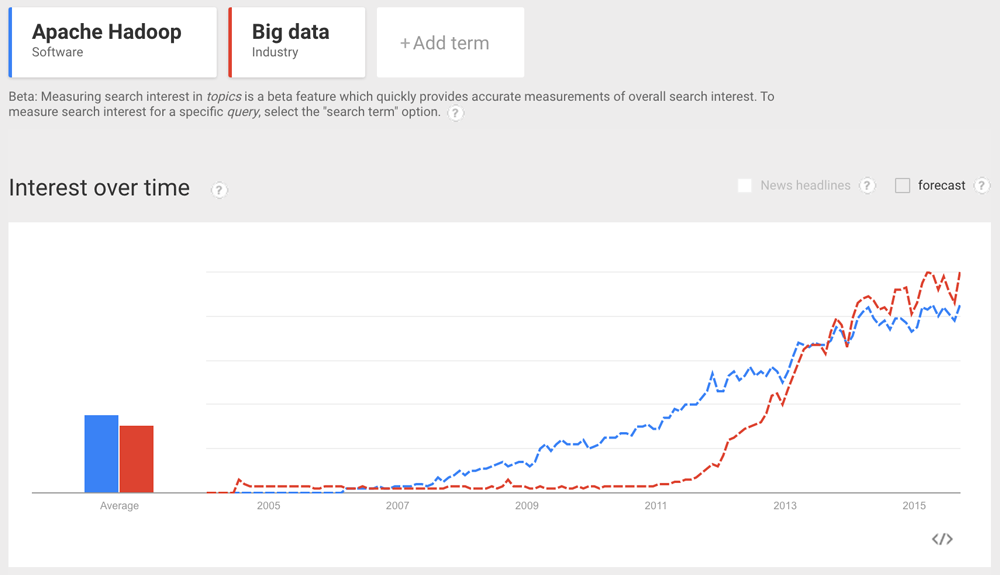
The rise of Hadoop was fairly meteoric, owing primarily to the fact that it enabled businesses to run analytics over datasets that were previously impossible to process due to their size.
Living with MapReduce
The past ten years have seen a huge boom in the big data industry, as demonstrated by the previous Google Trends chart. However, they have also highlighted several limitations with the MapReduce model:
- MapReduce ≠ data science platform
- MapReduce requires job pipelines
- MapReduce don’t do streaming
- Designed for massive datasets
MapReduce ≠ data science platform
If you talk to folk in the industry you hear the same story time and time again. The challenge is how to pull-through the work of data scientists, who are developing the analytics, into production Hadoop deployments quickly.
This problem arises because the data scientists typically work with Python, or R, and their associated libraries. Hadoop MapReduce is programmed in Java. This means that once the data scientists are finished Java developers need to translate the analytic, and any 3rd party libraries used, into Java and the MapReduce model. This takes a long time, and the pull-through to production is consequently slow.
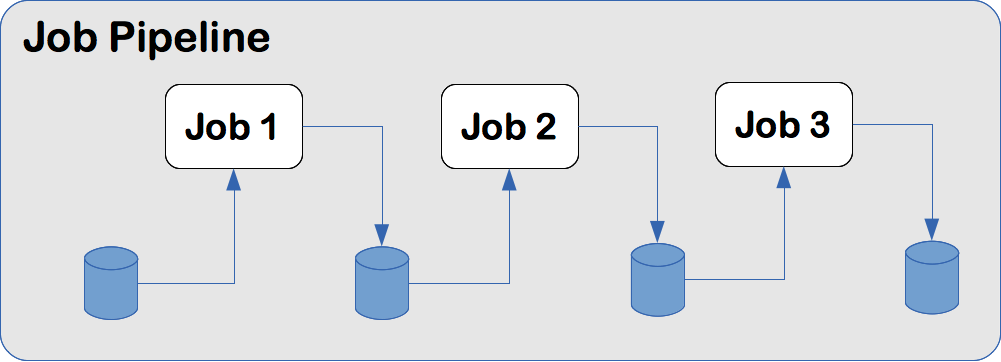
MapReduce requires job pipelines
MapReduce defines a low-level API of very basic building blocks. In a sense, this is necessary due to the properties that MapReduce jobs require to be distributable across a cluster of machines.
However, the result is that most algorithms must be decomposed into multiple MapReduce jobs. This presents two challenges. Firstly, the pipeline of jobs must be managed and coordinated2. Secondly, each job will write its output to disk. The next job in the pipeline must then read the data from disk, before processing it. This is a massive inefficiency, as disk IO is very slow compared to memory access.
MapReduce don’t do streaming
MapReduce is a batch processing model, it processes historic data. It can take hours to compute a result. It is not able to perform near realtime processing of streaming data and Complex Event Processing. As a result, organisations are often forced to deploy a separate stream processing platform, such as Storm or Samza.
This presents two challenges. The first is the deployment and support of a second large scale data processing framework, possibly operating on shared compute resources. The second is that the same analytic may need to be deployed to both the batch and streaming platforms. This requires the analytic to be written twice, as the programming APIs/models are different3.
Designed for massive datasets
MapReduce was designed around Google’s petabyte-scale datasets. As a consequence, it’s a disk-centric model. The reality is that most companies aren’t ‘webscale’. They don’t have petabyte-scale datasets. Quite often the datasets they are processing could fit in RAM on a moderately sized cluster.
For these companies, MapReduce is overkill and inefficient due to the level of disk IO required to process their data. Enter Spark.
AMPLab Awesomeness
In 2009 UC Berkeley AMPLab started to develop Spark, which provides a large-scale generalised data processing engine designed to address many of the previously mentioned limitations of MapReduce. The project was open-sourced in 2010, and a few years later became a top-level Apache project.
Spark has brought with it a step-change to data processing at scale, not unlike the step-change that Java brought as a general purpose computing language in the 1990s. In many ways, Spark is the Java of big data. As a platform it has both significant breadth and depth, which makes it hard to summarise. But I will boil down it’s core strengths into the following:
- In-memory Processing & Speed
- Comparative Simplicity of Programming Model
- Converged Data Science Platform
- Converged Programming/Analytics Model
- AMPLab Deep-Thinking
In-memory Processing & Speed
Spark is built around processing data in-memory. The pipeline of MapReduce jobs discussed earlier no longer need to write to disk between each stage of the computation. This makes Spark orders of magnitude faster than MapReduce for many workloads.
Further to this, Spark analytics are expressed as a series of data transformations. Much like the series of jobs in the MapReduce pipeline, except that the whole pipeline can be expressed in a single Spark job. Spark is then able to perform optimization over the whole pipeline, behind the scenes. Due to this, and many other optimizations4, Spark is significantly faster than MapReduce even when reading all data from disk.
Comparative Simplicity of Programming Model
Spark provides a functional programming model which is incredibly concise compared to MapReduce. Spark enables you to express an analytic in a couple of lines of code, that would require pages of MapReduce code.
Converged Data Science Platform
Spark provides a genuine opportunity for data scientists and big data developers to share the same platform. It does this by providing language support for both Python and Scala, with emerging support for R. This has significant implications for the speed of pull-through from research to production. It is hard to overstate the importance of this development.
In addition, Spark’s in-memory computation model suits the exploratory and iterative workflow and algorithms data scientists often utilise.
The emergence of web-based analytic notebooks5 (based on the iPython concept but supporting more languages) that integrate with Spark is also a huge boon. These notebooks provide an excellent way for data scientists to interact with the Spark platform, and provide the visualisations that are a core part of the data scientists workflow.
Converged Programming/Analytics Model
As a generalised data processing engine, Spark supports batch, stream and graph data processing models. In addition, Spark also supports structured data processing via Spark SQL and increasingly sophisticated machine learning via it’s MLib library6.
As a converged data platform, Spark enables maximum reuse of analytic code across different processing models. A write once, run on any model approach; although nothing is ever quite that simple.
AMPLab Deep-Thinking
The deep-thinking emerging from the UC Berkeley AMPLab is really exciting to see, and probably unparalleled in the big data industry. It is expressing itself not just through Spark, but in other cohesive big data technologies like BlinkDB7 and Tachyon.
AMPLab has placed people, as consumers and users of big data, at the core of their mission which is probably why they are delivering technological breakthrough that is not only making waves in academia but also out in industry too.
Databricks, the main commercial company behind Spark, was spun out of AMPLab in 2013. As you’d expect, they are continuing their charge of innovation and user-centric product delivery.
Does it end with Spark?
Almost certainly not. Spark clearly has mind and market share. However, as with any platform, it is not without limitations. Spark brings together the batch and stream data processing models by approximating streaming data processing via micro-batches.
This model works incredibly well for a number of use-cases. However, it breaks down when sub-second latency is needed.
The Kappa Architecture, promoted by Jay Kreps of Kafka fame (and others), turns this all on its head. Coming at things from the other direction, it reimagines batch processing as the reprocessing of large windows of streaming data. This has the advantage of providing super low-latency streaming platforms that are also capable of performing batch analysis.
Apache Flink and Apache Apex are just a couple of the platforms trying to make the case for the Kappa Architecture8. However, at the moment, it is unclear how much of the big data market is really concerned about sub-second streaming latencies and whether these platforms will gain significant traction.
At the moment, Spark is ruling the roost, and it looks set to stay that way.
-
IBM Announces Major Commitment to Advance Apache®Spark™, Calling it Potentially the Most Significant Open Source Project of the Next Decade ↩
-
A couple of examples of frameworks designed to help with this challenge are Oozie and Azkaban ↩
-
Twitter created Summingbird to address this issue, which enables them to write one analytic capable of being deployed on both MapReduce and Storm. ↩
-
See these links on Project Tungsten for more info on the latest performance work going on with the Spark platform. ↩
-
See Jupter and Apache Zeppelin. ↩
-
MLib probably warrants a post in it’s own right. Unfortunately, I’m running out of space so I’ll have to skip over Spark’s machine learning pipelines, etc. ↩
-
At the 2015 Spark Summit earlier this year, Databricks announced they are bringing the BlinkDB functionality to Spark. ↩
-
The Kappa Architecture can also be implemented using lower-level streaming frameworks like Apache Storm and Apache Samza. ↩
Tags: Spark Big-data Hadoop Flink Data-Engineering
comments powered by Disqus